如果有合格的致灾临界气象条件的历史序列数据,可以选择合适的概率分布函数计算致灾临界气象条件的概率。如果有部分合格的致灾临界气象条件的历史数据,可以采用信息扩散的方法计算概率。另外,还可以采用物理模型法、邻域类比法、经验估计等方法做气象灾害风险区划。
一、基于历史序列资料的风险区划方法
如果有30个以上符合平稳马尔科夫过程的致灾临界气象条件历史数据,选用合适的概率密度分布函数,能计算出致灾临界气象条件的概率或超越某一概率的致灾临界气象条件灾害最大等级的地理分布。举例如下:
1、天津、塘沽风暴潮的重现期概率计算
吴少华等(章国材,2010)采用51a(1950-2000年)的天津、塘沽验潮站资料,分别建立逐月和年极值的增水和高潮位的系列,采用Fisher/Gumbel概率密度函数,计算出不同重现期的天津、塘沽风暴潮和高潮位(表5.4和表5.5)。
表5.4 天津年(月)风暴增水的重现期值(单位:cm)
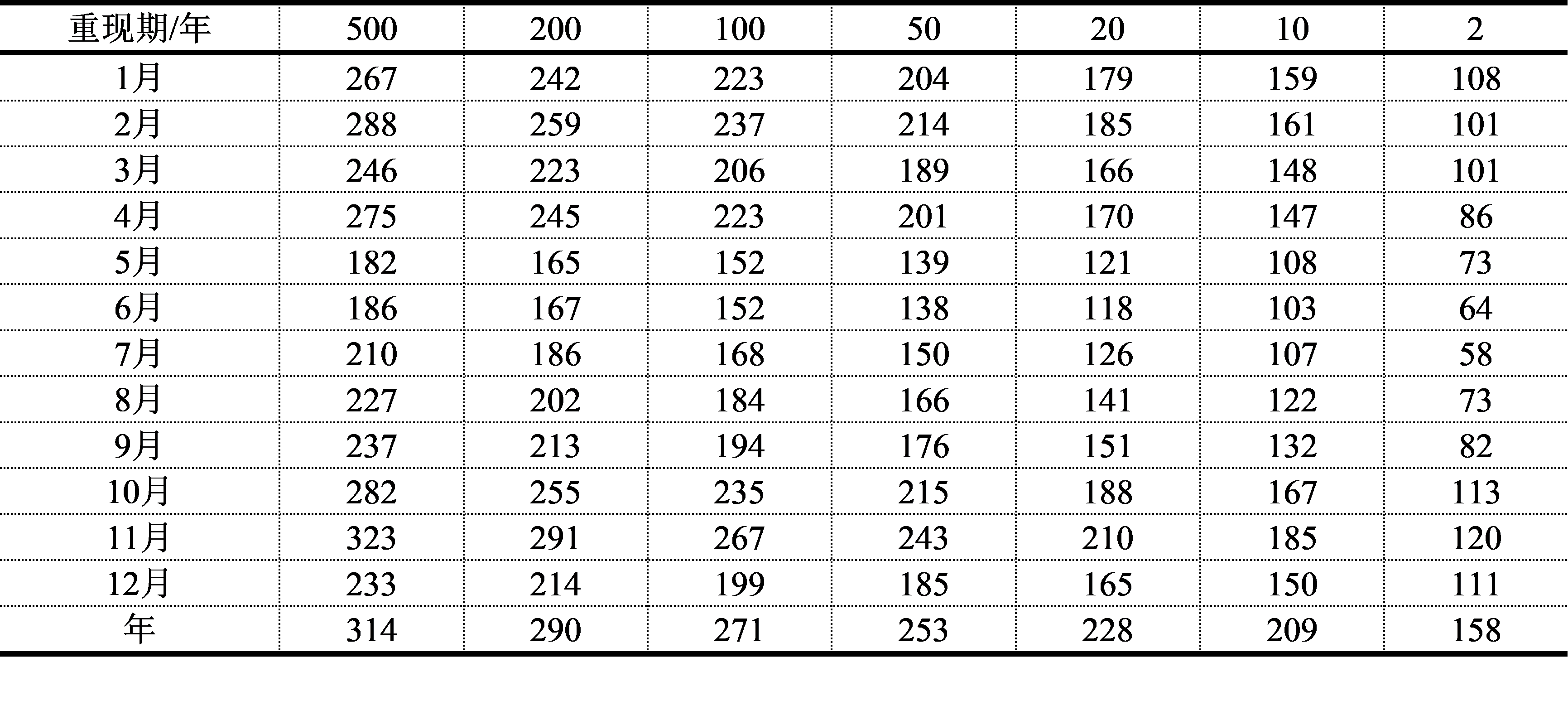
从表5.4中可知,天津沿海每年的2月、4月、10月和11月的增水重现期值较其余月份明显偏大,这说明:温带风暴潮产生的增水要大于台风风暴潮的增水。2月、4月、10月和11月是温带风暴潮发生的严重月份。
表5.5 塘沽年(月)高潮位的重现期值(单位:cm)
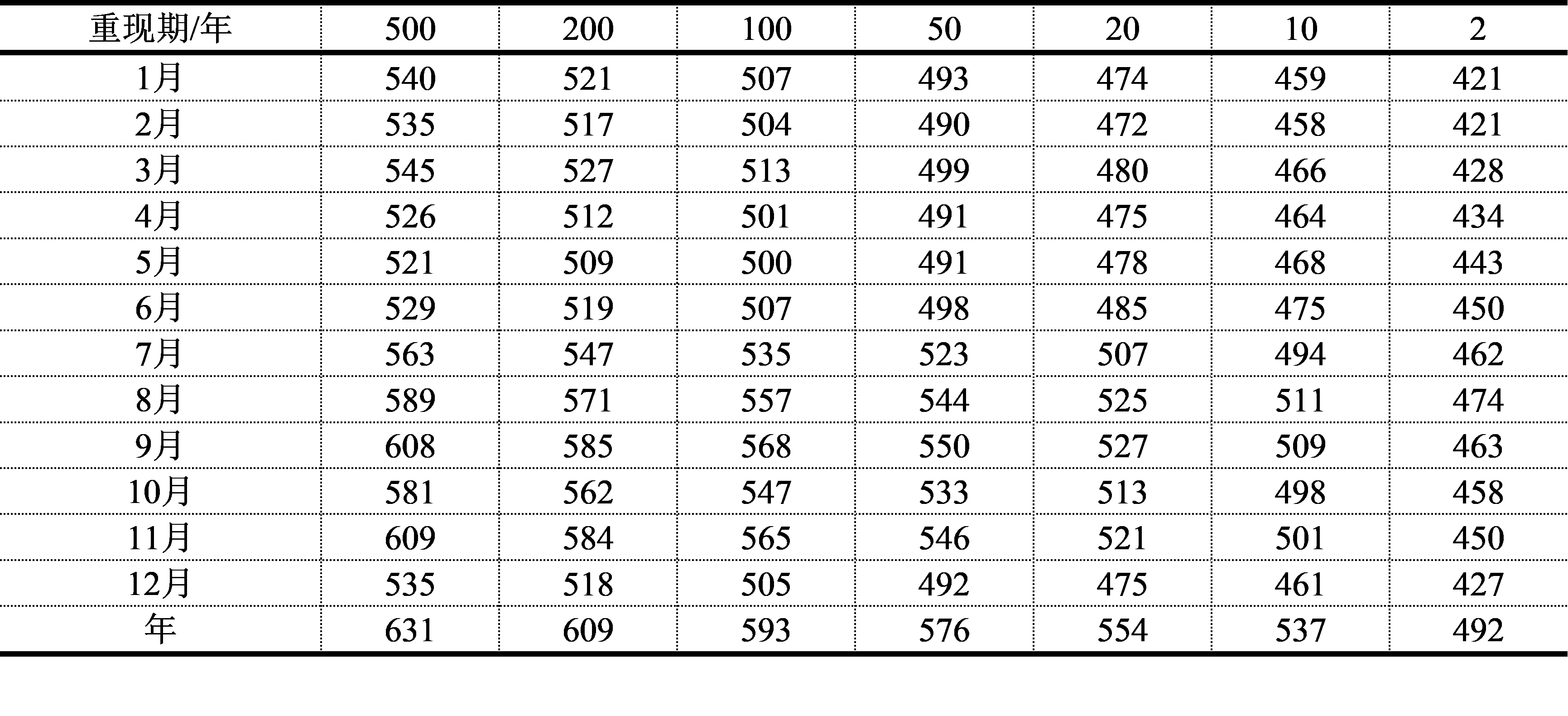
由表5.5可知,塘沽沿海的8月、9月、10月和11月的高潮位重现期值较大,8月和9月主要是由台风或台风登陆以后北上减弱为低气压所引起的高潮位,而10月和11月是由温带天气系统引起的高潮位。综合表5.4和表5.5可知,11月份是温带风暴潮最频发的时间,要严加防范历史上大的温带增水过程,大部分都发生存此月份。
分析研究表明,天津沿海是世界上风暴潮最频发区和最严重的区域之一,一年四季均有发生,夏季(主要是8月和9月)有台风风暴潮灾害发生,1992年9216号热带风暴影响天津沿海期间,罕见的风暴潮高潮位就越过闸顶,向市区漫溢。春、秋、冬季均有灾害性温带气旋引发的风暴潮,尤其要注意10月、11月、2月和4月的温带风暴潮过程。
由于多年的过量开采地下水引发地面沉降,天津沿海地区局部地段已与海平面持平,甚至低于平均海平面,致使防潮工程高度降低,防潮能力减弱。
天津市滨海新区是继浦东之后重要的经济开发区,风暴潮灾害已成为当地政府、有关单位和民众的一大忧患,为保护滨海新区不受千年一遇的风暴潮影响,需要修建6.5米高的防浪堤。
2、天津市沿海50年一遇的风暴潮风险分析
有了T年一遇的最高潮位,在精细的GIS的支持下,计算出在此潮位下的淹没范围和水深。仍以天津市沿海地区为例,最高潮位5.77m(相当于50年一遇,表5.5),天津市沿海淹没面积和不同水深淹没面积表5.6。图5.2是天津市沿海50年一遇的风暴潮淹没范围。
表5.6 天津市50年一遇的潮位淹没面积
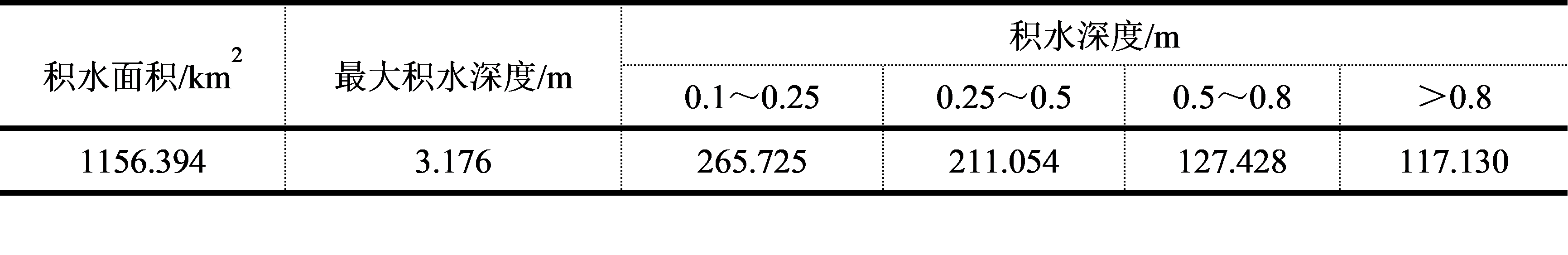
图5.2 天津市沿海50年一遇的风暴潮淹没范围
(黑色区)
根据不同验潮站保存资料完整性和准确性的不同,王喜年、吴少华等学者分别计算了中国沿海吕泗等17个验潮站不同重现期的风暴潮位和塘沽不同重现期的高潮位与风暴潮位。这些结果对当地防潮工程设计与防潮减灾有重要参考意义,已作为部分工程设计部门设计依据。可能最高风暴潮PMSS(Probable Maximum Storm Surge)的计算对我国沿海正在新建和拟建核电站设计高潮位的确定也至关重要。
如果能够获得全国各验潮站的历史资料,同样可以计算出每个验潮站2、10、20、50、100、200、500、1000、10000年一遇的高潮位的重现期值,从而得到我国沿海风暴潮风险区划图。
二、基于信息扩散的风险区划方法
1、信息扩散方法
如果样本不足30,为弥补信息不足所出现的问题,E.Parzen(1962)提出利用样本模糊信息对灾害样本进行集值化的、模糊数学处理的方法。信息扩散方法最原始的形式是信息分配方法,最简单的信息扩散函数是正态扩散函数。
信息扩散方法可以将一个分明值的样本点,变成一个模糊集。或者说,是把单值样本点,变成集值样本点。
设灾害指数论域为:
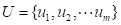 (5.28)
(5.28)
一个单值观测样本点x根据下式可以将其所携带的信息扩散给U中的所有点。
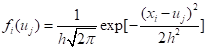 (5.29)
(5.29)
其中h称为扩散系数, 可根据样本集合中样本的最大值y和最小值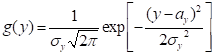 及样本个数m来确定,其计算公式如下:
及样本个数m来确定,其计算公式如下:
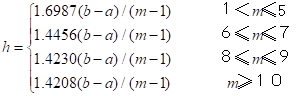 (5.30)
(5.30)
这里,
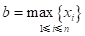 ,
, 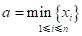 (5.31)
(5.31)
令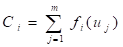 (5.32)
(5.32)
相应模糊子集的隶属函数是:
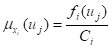 (5.33)
(5.33)
称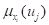 为样本点
为样本点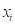 的归一化信息分布。
的归一化信息分布。
对进行处理,便可得到一种效果更好的风险评估结果。
令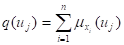 (5.34)
(5.34)
其物理意义是:由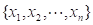 ,经信息扩散推断出,如果灾害观测值只能取
,经信息扩散推断出,如果灾害观测值只能取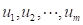 中的一个,在将均看作是样本点代表时(包括部分地代表在随机实验中没有出现的样本点),观测值为
中的一个,在将均看作是样本点代表时(包括部分地代表在随机实验中没有出现的样本点),观测值为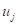 的样本点个数为
的样本点个数为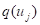 。显然通常不是一个正整数,但一定是一个不小于零的数。再令
。显然通常不是一个正整数,但一定是一个不小于零的数。再令
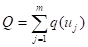 (5.35)
(5.35)
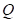 事实上就是各点上样本点数的总和,从理论上来讲,必有
事实上就是各点上样本点数的总和,从理论上来讲,必有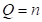 ,但由于数值计算四舍五入的误差,与n之间略有差别。可知,
,但由于数值计算四舍五入的误差,与n之间略有差别。可知,
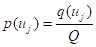 (5.36)
(5.36)
式中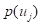 就是样本点落在
就是样本点落在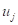 处的频率值,可作为概率的估计值。超越的概率值是:
处的频率值,可作为概率的估计值。超越的概率值是:
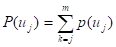 (5.37)
(5.37)
式中就是要求的某一种灾害超越概率风险估计值。
2、湖南农业的水旱灾和广东风暴潮风险区划
黄崇福等针对小区域内历史灾情资料不多的特点,引入了信息扩散的模糊数学方法,对湖南农业的水旱灾风险和广东风暴潮风险进行了研究。
(1)湖南农业的水旱灾风险分析
利用民政部农村自然灾害情况统计表所提供的农业灾情资料,对历史灾情资料进行优化处理,根据农业灾情数据库和摘自湖南省统计年鉴的经济背景数据库,对湖南省的各县市获得14年的资料。
设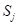 (j=1,
2,…,14)分别为1979、1980、1981、1982、1983、1984、1985、1987、1988、1989、1990、1991、1992、1993年的旱灾受灾面积,为相应年份的播种面积,则旱灾受灾指数为:
(j=1,
2,…,14)分别为1979、1980、1981、1982、1983、1984、1985、1987、1988、1989、1990、1991、1992、1993年的旱灾受灾面积,为相应年份的播种面积,则旱灾受灾指数为:
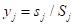 (j=
1, 2,…, 14) (5.38)
(j=
1, 2,…, 14) (5.38)
为了计算机计算的方便, 并考虑计算精度的要求, 取受灾指数论域为:
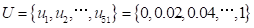 (5.39)
(5.39)
分别将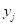 按式(5.29)、(5.30)和(5.31) 进行处理, 求得它们的归一化信息分布
按式(5.29)、(5.30)和(5.31) 进行处理, 求得它们的归一化信息分布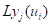 。
。
再利用式(5.32)~(5.37),即可求出旱灾受灾风险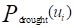 。
。
应用地理信息系统软件Mapinfo,将计算所得的数据制成风险图。它是以同等受灾程度为基础,以不同超越概率值来标明地区差别的图件。
表5.7中标志5%的一列意思是今后每一年中,旱灾受灾面积/播种面积≥5%的概率;10%意思是今后每一年中,旱灾受灾面积/播种面积≥10%的概率,依此类推。以旱灾受灾指数为35%这个风险水平下的风险图为例,由表5.7可知,衡阳的风险值为0.2025。可以解释为在衡阳地区几乎每5年就要遇到一次受灾面积超过35%的旱灾。
表5.7 湖南省旱灾受灾风险估计值

(2)广东沿海台风风暴潮灾害风险
选择6个验潮站作为代表站进行广东省沿海地区台风风暴潮灾害的风险评估。其中,汕头站和汕尾站代表粤东沿海,赤湾站和黄埔站代表珠江口地区,湛江站和南渡站代表雷州半岛东岸地区。选用各代表站1949—2005年的台风风暴潮最大增水值序列资料作为各站的观测样本,表5.8中各站的最大增水值样本不一致,如汕头只有8个样本,而汕尾有18个样本,这些站点的样本都属于小样本,远远达不到传统方法对样本数目的要求。基于各站的台风风暴潮灾害记录样本是小样本的情况,采用基于信息扩散理论的风险评估模型对台风风暴潮灾害风险进行评估。
将台风风暴潮的最大增水值作为风暴潮灾害强度指数.设
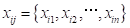
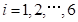 ;
;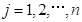
分别为各测站历次台风风暴潮灾害的最大增水值。
根据台风风暴潮最大增水值的变化范围,把一维实数空间上的集合[0.5,4]作为的论域并将连续论域[0.5,4]按等间距取点,转变为离散论域。考虑到计算精度的要求,取8个控制点(n=8),构成离散论域:
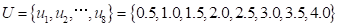
各验潮站台风风暴潮的最大增水的样本个数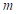 、样本最大值a、样本最小值b、以及扩散系数h,如表5.8所示。
、样本最大值a、样本最小值b、以及扩散系数h,如表5.8所示。
表5.8 台风风暴潮风险评价有关参数
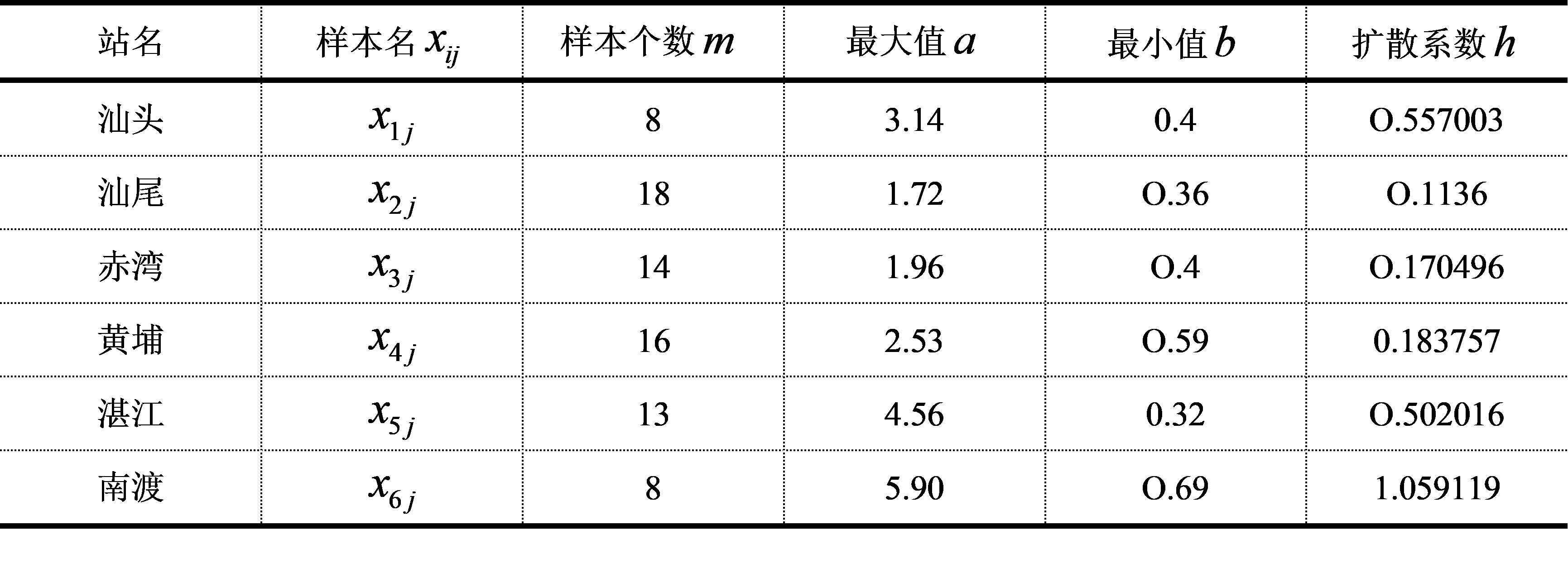
根据公式(5.32)~(5.37)计算,可以得出广东省沿海各验潮站台风风暴潮的最大增水的风险估计值(表5.9)。
由表5.9分析得出,雷州半岛东岸的南渡站台风风暴潮的最大增水在各个风险水平的风险估计值均大于其它各验潮站。在[0.5,2.5]这一风险水平区间,粤东沿海的汕头站台风风暴潮的最大增水的风险估计值略高于雷州半岛东岸的湛江站,而在[2.5,4.0]这一风险水平区间,汕头站台风风暴潮的最大增水的风险估计值略低于湛江站.珠江口的赤湾站和粤东沿海的汕尾站的台风风暴潮的最大增水的风险估计值在各个风险水平上均低于其它验潮站.这一结果与各验潮站台风风暴潮发生的实际情况基本吻合。
表5.9 风暴潮灾害风险估计值
将基于信息扩散技术的风险计算结果与基于风暴潮数值预报的风险计算结果(1949—1991年的台风风暴潮增水序列采用Fisher/Gumbel极值分布函数而得出的估计值)进行比较,发现两种方法的计算结果都与实际风险情况基本吻合。广东省沿海是台风风暴潮灾害的频发区和严重区,尤其是雷州半岛东岸、粤东的饶平、澄海,汕头一带、以及珠江口三个岸段。
三、基于物理模型的风险区划方法
如果某个物理/生物模型能够较好地描述灾害事件过程,则可以用这个物理/生物模型去编制该灾害的风险区划。
例如,侵蚀--生产力影响评估模型(Erosion Productivity Impact Calculator,EPIC)是1984年美国农业部研制的水土资源管理和作物生产力评价模型。适合于模拟作物轮作、耕作实践、种植日期、灌溉和施肥策略等(Williams J R等,1989)。
致灾因子危险性评价采用“水分胁迫”作为刻画其致灾因子强度的主要因子。由于水分胁迫的大小和胁迫的天数共同影响了作物在一个生长季内的干旱强度,因此,在不灌溉情景下,从日输出结果中提出每个生长季内受水分胁迫影响的当天的水分胁迫值和天数,构建了HI指数作为农作物旱灾致灾因子评价的指标:
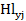 =
=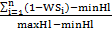 (5.40)
(5.40)
式中:Hl为作物生长季内的干旱致灾强度指数,为y年第j站的干旱致灾强度指数,WSi为第i天受水分胁迫影响的当天的胁迫值,n为生长季内受水分胁迫影响的天数,maxHl和minHl分别为所模拟的所有站点所有年份内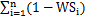 的最大值和最小值。
的最大值和最小值。
自然脆弱性评价根据EPIC模型的特点,先控制养分和通气性胁迫,然后设定:完全满足养分与完全满足水分(Y1情景)和完全满足养分与雨养即不灌溉(Y2情景),分别进行模拟产量,利用Y1减去Y2的产量,认为是达到了剔除气温胁迫对作物生长的影响,只受水分胁迫影响的玉米产量损失值。该值与各站点的多年最大产量的比值即为干旱产量损失率:
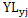 =
=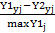 (5.41)
(5.41)
式中,为第j站y年因干旱导致的单位产量损失率,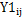 为第j站y年完全满足养分和水分情景的单位产量,
为第j站y年完全满足养分和水分情景的单位产量,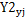 为第j站y年完全满足养分与不灌溉或雨养情景的单位产量,max
为第j站y年完全满足养分与不灌溉或雨养情景的单位产量,max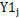 为第j站多年最大单位产量。
为第j站多年最大单位产量。
贾慧聪等(2011)对EPIC模型进行空间尺度校验。用于EPIC模型校验的数据有:①模型的相关参数(耕作参数、作物参数和施肥参数等);②基本输入数据:日气象数据(含天气生成器数据)、土壤数据、田间管理操作的数据等。施肥量数据来源于2001年中国农业数据库,主要包括氮肥、磷肥、钾肥和复合肥。玉米的潜在热量单位(PHU)选择2200度。灌溉方式设定为均采用自动灌溉。基于获得的已有数据,用2001年统计产量数据和模型模拟的产量进行对比验证,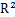 相关系数为0.5222。这样的模拟精度已经达到了满意水平。
相关系数为0.5222。这样的模拟精度已经达到了满意水平。
然后,模拟黄淮海夏播玉米区内8km网格单元上1960—2005年玉米的生长过程,并提取每年每个生长季内受水分胁迫影响日的水分胁迫因子值,得出每个生长季的致灾强度指数,结合典型玉米品种的自然脆弱性曲线,计算研究区玉米受旱灾打击的产量损失率。
在此基础上,通过计算每个评价单元减产损失的超越概率,得到玉米种植区不同致灾水平下的成灾风险系列图,包括2年一遇、5年一遇、10年一遇和20年一遇的风险区划结果。
四、邻域类比法
有些气象灾害可能30年也不会出现一次,短历史时期没有出现的灾害,不等于将来不出现,这种灾害的风险依然存在。例如卡特琳娜台风引发的强风暴潮给美国新奥尔良市造成了“灭顶之灾”,莫拉克台风的强降水重创台湾南部,河南“75.8”特大暴雨造成河南省板桥等水库垮坝并造成重大人员伤亡,这些都是100到1000千年一遇的灾害,虽然影响的只是局部地区,未来其它地区是否也会受这种强气象灾害的影响也很受关注。
邻域类比法提供了一种研究历史上没有记录到某种灾害的地方是否会出现这种灾害的可能方法。
1、邻域类比法思路
邻域类比法思想基础是,尽管实际降水或大风过程的雨量或风力空间分布不均,但是从较长历史时期考察,相同气候地质地理生态区中的任何地方都有可能发生类似等级的降水或风力。
但是,不能由此推论致灾临界条件都相同。因为致灾临界条件与孕灾环境和防灾工程紧密相关。例如,尽管相同气候地质地理生态区中可以产生相同的极值降雨量,但是下垫面的细微差异(有河沟或排水沟)便可导致内涝的临界面雨量不同。
对于气象条件,邻域类比法的应用必须符合以下条件:
(1)相同气候区;
(2)相同天气条件,包括相同天气形势和物理条件;
(3)相同孕灾环境,包括地理条件相同、地质条件相同、生态环境相同;
(4)相同能力人类防灾工程。
2、天津市区内涝风险区划
根据天津市气象观象台的观测资料分析,每年天津市区出现暴雨的次数不多,降水量级在50~74.9mm之间的普通暴雨的重现期为0.78 a,即平均每年1~2次,而更大雨量降水的重现期更长。天津市的暴雨次数虽然少,但短历时、突发性的局地暴雨过程较多,暴雨强度往往较大,常出现几个小时100mm以上的大暴雨。
天津市位于华北平原,市内各区气候和地理条件相同,尽管每次降水过程的雨量空间分布不均,但从长时期考察,城区各地都有可能出现类似等级的降水,这是邻域类比法的思想的典型体现。为此,解以扬等(章国材,2010)在城市内涝模拟时假设各降水过程的降水量空间分布均匀,以比较不同区域内涝程度的差别。
风险分析的具体方法如下:
(1)分析暴雨等级分布特征。暴雨以日降水量来划分等级,将大雨以上降水按25mm一个量级,划分成7个等级,统计不同等级内的出现频次。对频次取对数,建立频次的对数与降水等级之间的关系。
(2)根据降水等级出现的概率P计算该等级降水的重现期(为该等级降水出现概率的倒数,即T = 1/P)
(3)按照现有城市建设和排水系统状况,选择历史上不同重现期的短历时降水过程代入暴雨内涝仿真系统进行模拟。
(4)分析不同重现期强降水的灾情分布情况和灾害等级,进行风险评估和区划。
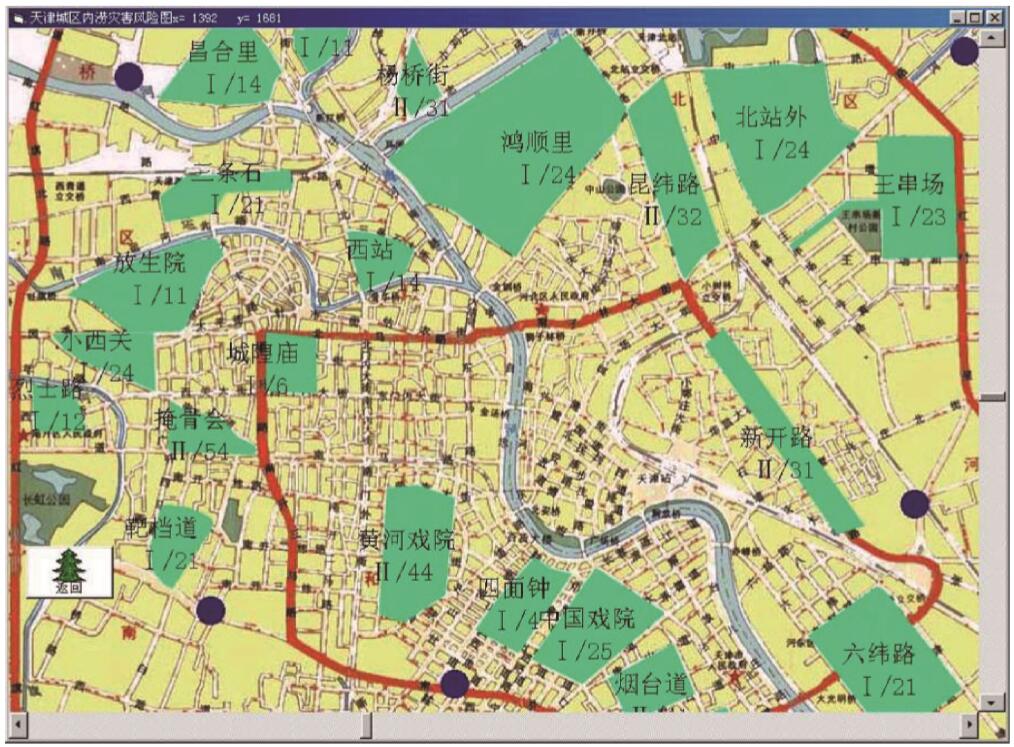
图 5.4 天津市暴雨重现期为一年的积水灾害风险图
模拟结果表明,同等强度的暴雨过程对市区不同地方会造成不同程度的内涝灾情;在不同暴雨过程中随着暴雨强度增加,多数地区的灾情也有不同程度的增加。市区暴雨内涝的灾情风险以Ⅰ级和Ⅱ级为主,降水量未达150 mm时,通常不会出现Ⅲ级的灾情风险。50~124.9 mm的降水的重现期为1~5a,经常容易发生,而对应的Ⅱ级灾情风险的比例已达19%~36%,对城市交通和人民生活有一定影响,排涝减灾的任务较重。研究人员绘制了天津市区重现期为一年一遇的暴雨内涝灾害风险区划图(图5.4)。图中红色线段为主要干道;蓝色线段为河道;绿色阴影区为积水区,其中的标注分别是地段名称、灾害等级/积水深度。
该天津市内涝风险区划是在假设初始海河河道水位1.0m(注:模型中高程坐标系均选用大沽高程系)时,仅考虑市内降雨不考虑上游来水时的风险,如果考虑海河上游的来水或海河河道水位更高,则风险要更大。如果考虑海河洪水不同重现期的基础上叠加天津市区不同等级的降水,则可以应用内涝物理模型得到各种可能条件下不同的内涝风险区划。
当天津市区排水条件发生重大变化时,必须用水文动力内涝模型重新模拟,得到新的内涝风险区划。
邻域类比法适用条件有两个要点:
(1)类比的区域必须是“邻域”,即很靠近曾经出现过灾害的区域。对于气象灾害而言,邻域与灾害发生的区域必须同处于一个气候区,地形地貌、地质和生态条件相似。显然天津市各区是符合这个条件的。
(2)类比的要素和方法不能受下垫面及排水条件的影响。例如,较长历史时期,相同气候区有相同的气候规律,可以出现相同的降水量等级分布,这是可以类比的。如果各对比区下垫面沟渠的河套参数(長短、宽窄、沟深)、排水设施参数不同,致洪的临界面雨量就会不同,致洪临界面雨量则不能类比。
五、经验估计法
有些气象灾害出现很少,又没有正式记录,判断这种灾害出现的概率可以采用经验估计法。
例如,编制社区、村屯的灾害风险区划,主要依据当地居民的经验,包括以下方面:
1、对过去灾害的回顾分析
按本地灾害发生的频率排序,并对灾损进行分析。可以寻求当地有亲身经历的人员的帮助。这是很重要的一步,是备灾、减灾计划的基础。
2、编制灾害的季节历
根据曾经发生的灾害事件,按月编制灾害的季节历,即每种灾害最可能在哪些月份发生,它可以为备灾和模拟演习提供依据。
备灾型社区、村屯的一项重要工作即是绘制当地的风险地图、脆弱性地图和救灾能力地图。气象部门技术人员应当主动向当地人搜集一些基础数据,在他们的协助下绘制这些专业地图。
在制图之前,社区、村屯成员应当讨论以前遇到灾害时的经验,使得各自的灾害记忆形成一致的、客观准确的灾情信息。
这种地图不需要精确测量,包含以下内容即可:
(1)风险和脆弱性地图:在脆弱性地图中标识出社区容易发生的灾害及容易受灾的地方,划出低洼地、近水地等。通过这样的制图,社区成员可以明确在各种灾害中需要保护的资产。
(2)安全出口和路线图:社区成员应标出社区中的安全地区,如坚固的建筑、凸地等。在躲避灾害时,这些地方可以成为人们的避难所。还必须在图中标出紧急情况发生后用于避难的预备通道。
(3)资源地图:包括资源描述、分布状态和运达的路径。