本节介绍气象灾害风险区划的理论,以及与防灾减灾需求的一致性问题。
一、气象灾害风险区划定义
区划是研究某种事物时间上的演替和空间上的分布规律,对其空间范围进行区域划分的过程。气象灾害区划是根据过去发生过的气象灾害事件,按照气象灾害在时间上的演变和空间上的分布规律,对其空间范围进行区域划分的过程。它并不涉及气象灾害未来的情景。
未来气象灾害发生概率是表示未来气象灾害发生的可能性最恰当的表达方式。因此,气象灾害风险区划是反映若干年内可能达到的气象灾害风险程度,即某地区可能发生的气象灾害的概率或超越某一概率的气象灾害最大等级。
二、国外气象灾害风险区划概况
国外学者对气象灾害风险区划的研究,大多是针对单一灾害类型(如洪水、滑坡等)的研究。研究较多的是洪水风险区划,许多国家都编制了全国或区域性洪水风险图。日本于1977年制定了“综合治水对策”,在特别重要的河段上编制了洪水风险图,指出了100~200年一遇的洪水淹没范围,并逐步推向了全国。欧州一些国家从20世纪70年代开始采用水文、水力学数值模拟方法编制全国洪水风险图。加拿大、澳大利亚等国编绘的洪水风险图标出了20年一遇和100年一遇的洪水淹没范围;美国的洪水风险图中指出了10年、50年、100年、500年一遇的洪水淹没范围。目前经常使用的以淹没图为主的洪水风险图,大部分没有进行不确定性意义下的风险分析,实际上是洪水强度区划图,是某一地域可能发生的水害的危险程度,或是预测在发生某种洪水或在洪水调动、工程失事等情况下该地域遭受的洪水危险程度。
其它灾种如干旱、林火、滑坡、泥石流等也有不少研究成果。
三、气象灾害风险的数学描述
在统计模型里,气象灾害风险的数学描述如下:
设X 为气象灾害指标,T 年内关于X 的超越概率的空间分布定义为气象灾害风险区划。记
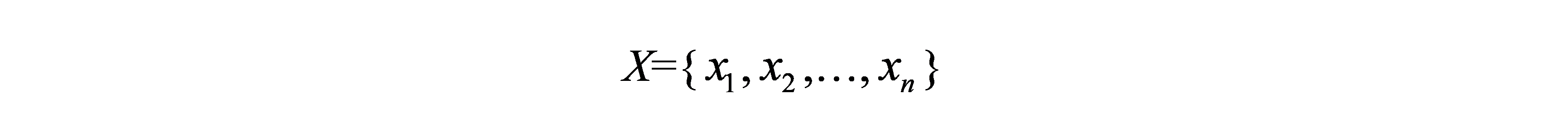
又设超越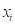 的概率P(X≥)为
的概率P(X≥)为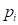 ,i=1, 2,…,n, 则概率分布
,i=1, 2,…,n, 则概率分布
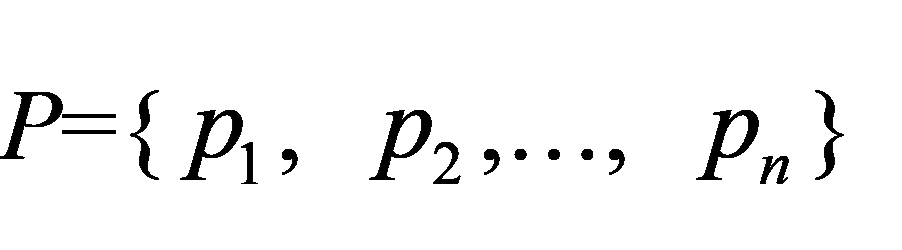 (5.1)
(5.1)
就称为气象灾害风险概率分布。风险区划就是分析风险概率的空间分布。
四、样本问题
为了求概率,必须有合格的历史样本。所谓合格,一是历史样本应当有一定的长度,二是历史样本系列必须是平稳概率分布。
1、样本长度
通常的概率风险分析方法要求有30个以上样本,否则分析结果将极为不稳定,甚至与实际情况相差甚远。
当研究区域是省或省以上的基本单元时,由于有长序列气象、水文、海洋、地质等观测资料的支撑,使用通常的概率统计方法一般就可以做出风险区划。但是,大区域的平均结果掩盖了区域内的许多差别。如果评估的基本单元缩小到县市以下的较小区域,将碰到历史资料严重不足的问题。
在我国境内,一般一个县(市)仅有一个气象站具有30年以上的历史资料。2005年之后,气象部门虽然建了不少区域自动气象站,但因为时间短、气象要素不全等问题,其观测资料对于风险区划的适用性有很多局限。水文部门在大中河流上建的水文站资料长度在30年以后,但是在小型河流上水文站很少,山洪沟自动水位站建设也刚起步。沿海验潮站分布稀疏,用于评估沿海风暴潮的风险密度不够。对于县以下的区域,虽然近几年灾情资料比较齐全,但是致灾因子的历史资料不完备,研究致灾临界气象条件的地理分布难度很大。
2、样本的平稳马尔科夫随机过程问题
如果我们用观测资料作样本计算风险的概率密度分布,其前提是假定了相应的风险系统变化是平稳马尔可夫随机过程:即风险系统未来的发展状态只与过去T年的风险系统情况有关,而与更早以前的风险系统情况无关,并且,相应的概率规律不因时间的平移而改变。如果此假定符合实际,人们自然可以用过去T年的风险系统资料,推算未来T年内的风险。
因此,应该对历史样本进行平稳马尔可夫随机过程的假定进行符合性检验:
马尔科夫概率模型应用多元时间序列分析和马尔科夫过程的理论,从实测时间序列中抽象出随机过程的概率规律。具体计算过程如下:
(1)采用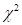 统计检验方法,检验待分析的时间序列是否具有马尔科夫性质,即无后效性;
统计检验方法,检验待分析的时间序列是否具有马尔科夫性质,即无后效性;
以历史实测资料,统计各个状态之间的转移概率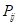 ,得到转移概率矩阵
,得到转移概率矩阵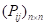 ;计算各状态的极限分布:
;计算各状态的极限分布:
P=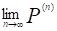 (5.2)
(5.2)
计算状态i和状态j之间的置换系数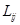
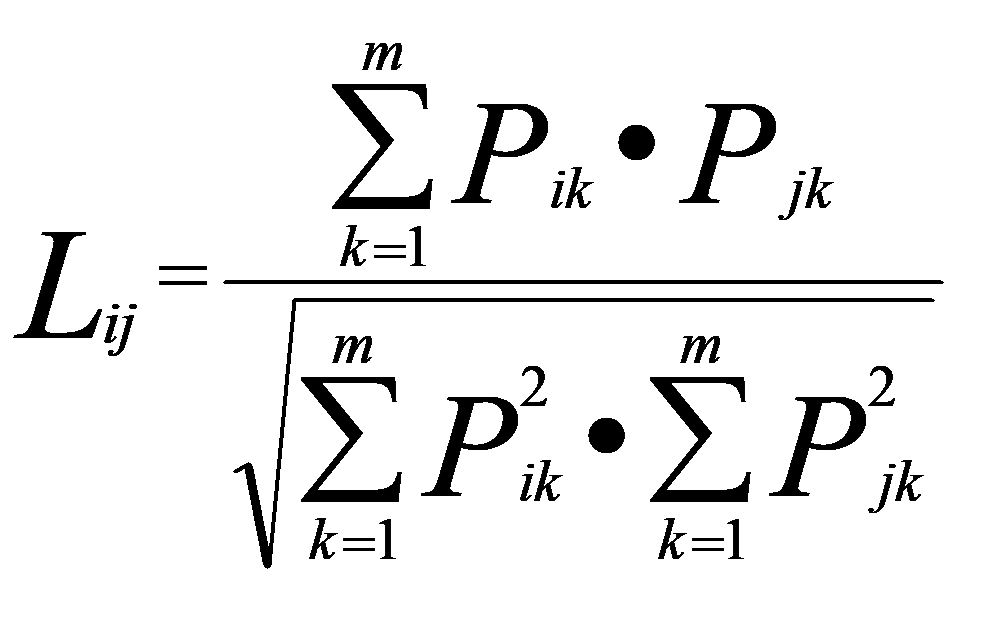 (5.3)
(5.3)
式中: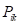 、
、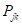 分别表示状态i和状态j转移到状态k的概率,越接近于1,状态i和j在序列中的地位的相似性越高;越接近于0,表明这两个状态很不相似,因此是考虑状态i和j动态变化相似性程度的指标。
分别表示状态i和状态j转移到状态k的概率,越接近于1,状态i和j在序列中的地位的相似性越高;越接近于0,表明这两个状态很不相似,因此是考虑状态i和j动态变化相似性程度的指标。
(2)用相关系数统计检验的方法检验各状态之间互相转换的显著性,并据此对各状态加以分类。
五、气象灾害风险区划的理论分析
第h类气象灾害对第i类承灾体的风险的形式表达式如下:
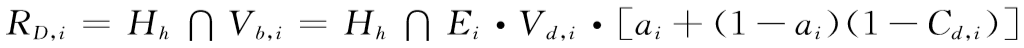 (5.4)
(5.4)
在(5.4)式中,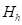 为第h种气象灾害的致灾危险性,由第h种气象灾害强度和发生概率度量。除了兴建新的防灾工程和孕灾环境发生了明显的变化之外,一般来说,气象灾害的致灾危险性的概率是存在的,只要致灾临界气象条件有超过30个历史样本,这些历史资料序列样本符合平稳马尔科夫随机过程,可以选用合适的概率密度函数,求得社会若干年内可能达到的气象灾害风险程度,即某地区可能发生某等级气象灾害的概率或超越某一概率的气象灾害最大等级。
为第h种气象灾害的致灾危险性,由第h种气象灾害强度和发生概率度量。除了兴建新的防灾工程和孕灾环境发生了明显的变化之外,一般来说,气象灾害的致灾危险性的概率是存在的,只要致灾临界气象条件有超过30个历史样本,这些历史资料序列样本符合平稳马尔科夫随机过程,可以选用合适的概率密度函数,求得社会若干年内可能达到的气象灾害风险程度,即某地区可能发生某等级气象灾害的概率或超越某一概率的气象灾害最大等级。
与人类社会系统有关的风险系统的随机过程显然不是平稳马尔可夫过程。因为社会发展造成了人口分布、经济发展程度、财产密度及物价的变动等问题,每种承灾体的物理暴露的历史演变都不相同,这种经济社会发展的非平稳性,以及承灾体脆弱性的历史变化,导致承灾体物理暴露的历史变化显然不是平稳马尔科夫过程。例如,房屋抗灾能力30年来变化非常大,显然不是平稳马尔科夫过程。随着经济社会高速发展和国力增强,我国的防灾减灾能力明显提升,防灾减灾能力的历程也不是平稳马尔科夫过程,不可防御的气象灾害风险亦然。所以,很难求出承灾体物理暴露、脆弱性和人类社会防灾减灾能力的概率。即便能够求出它们的概率,由于与致灾危险性的概率意义不同,求它们乘积出现的概率,既不可能,从理论上讲也无意义。总之,包含了承灾体物理暴露、脆弱性和人类防灾信息的历史资料不是平稳马尔可夫过程,不能用过去T年的资料去推算未来T年内的风险。
因此,理论上只能求致灾危险性的概率,即某地区致灾临界条件的概率或超越某一概率的致灾临界条件的最大等级。总之,气象灾害风险区划实际上是致灾临界气象条件的概率或超越某一概率的致灾临界气象条件最大等级的地理分布。也只有这种风险区划才能为人类社会防灾减灾所用,比如为城乡规划和开发区、产业布局提供依据,为城镇、居民点、重要设施和重大工程建设提供规避气象灾害高风险区建议以及防御工程标准等。
理论结论与实际需求的一致性才是风险区划的正确选择。
六、气象灾害风险区划的内容和流程
风险区划应当包含如下内容:
(1)确定致灾临界气象条件。由于灾害的发生不仅与致灾因子有关,还依赖于人类社会所处的自然地理环境条件以及防灾设施的能力。因此在自然地质地理条件发生变化以及兴建防灾工程后,必须重新研究致灾临界气象条件。
(2)获取区划范围内每个格点30个以上致灾临界气象条件历史样本,确定它们的概率或超越某一概率的灾害最大等级的地理分布。孕灾环境和防灾工程发生明显变化时,需要重新制作风险区划。
(3)评估在各种超越概率下各类承灾体的风险。应尽量多地评估对灾害较为敏感的承灾体的风险,得到不同承灾体的风险空间分布图。当承灾体的易损性发生明显变化时,应当重新评估风险。
(4)提出防御措施。对于每一种气象灾害风险区划,都应当指出哪些地区是灾害高风险区,可能会对居民点、工程建设等敏感和重要承灾体有什么不利影响,在未来规划开发建设应引起注意;如果确有必要建居民点、开发区或者承灾体已经存在,应当给出防御工程的建设标准等针对性建议,以规避风险。
风险区划流程如下:
(1)研究致灾临界气象条件。孕灾环境和人类防灾工程发生变化后,应当重新研究致灾临界气象条件。
(2)收集30年以上气象、水文等资料,釆用科学的物理内插方法,分析研究区域内每年每个格点致灾临界气象条件的数值,得到每个格点致灾临界气象条件数值的历史序列。
(3)研究致灾临界气象条件历史序列的概率分布特征,选取最适合的概率密度函数;计算每个格点不同等级致灾临界气象条件的出现概率或超越某概率的致灾临界气象条件最大数值,得到不同等级致灾临界气象条件的出现概率或超越某概率的致灾临界气象条件最大数值的地理分布。
(4)收集当前每种承灾体的物理暴露数据(暴露于气象灾害之中的承灾体的数量和价值量),收集和研究每种承灾体的脆弱性曲线;评估每种敏感承灾体在不同超越某概率下的物理暴露和可能的损失,编制不同承灾体在不同超越概率下的风险图谱。
当承灾体的物理暴露或脆弱性发生变化后,应当重新评估每种承灾体的风险。
(5)根据不同等级致灾临界气象条件的出现概率或超越某概率的致灾临界气象条件最大数值的地理分布及其可能出现的风险,提出防御和减轻气象灾害的措施。
对于每一种自然灾害风险区划,都应当指出哪些地区是自然灾害高风险区,不适合建居民点、开发区和工程;如果确有必要建或者承灾体已经存在,应当建什么标准的防御工程,以避免灾害风险的影响;设计避难所和转移路线,根据医院和物质的地点,设计伤员和物资的输送通道等。
例如,洪水风险区划要研究的是10、20、30、50、100、200、500年一遇的洪水淹没范围和水深。根据洪水风险区划,在城乡规划中易受水淹的地区便不能兴建居民点、工程和旅游设施。如果确需在洪水易淹区兴建居民点、工程和旅游设施或者已经存在城镇等承灾体,就应该根据洪水风险区划和需要保护的承灾体的重要性,确定修建防洪堤的范围和高度。
七、概率密度分布函数
如果致灾临界气象条件的历史资料比较齐全(包括空间和时间分布),且样本数超过30个,就选用适当的概率密度分布函数求得各地致灾临界气象条件的出现概率,从而得到气象灾害风险区划。下面介绍几种常用的求致灾临界气象条件概率的方法:
1、频率统计法
此方法以数理统计学中的大数定律和中心极限定理为理论基础,认为在样本足够大时,可以用灾害事件发生的频率作为灾害危险性的无偏估计。
(1)计算公式
① 计算致灾因子(临界气象条件)强度的出现频率
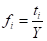 (5.5)
(5.5)
式中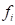 为第i等级的致灾因子强度(临界气象条件)出现的频率,
为第i等级的致灾因子强度(临界气象条件)出现的频率,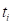 为在统计年限Y内第i等级的某种致灾因子强度(临界气象条件)出现的次数,Y一般要求30年以上。当≤1时,一般采用多少年一遇来表示。
为在统计年限Y内第i等级的某种致灾因子强度(临界气象条件)出现的次数,Y一般要求30年以上。当≤1时,一般采用多少年一遇来表示。
② 当数据质量不足以进行以上定量分析时,可以按照达到某一致灾因子强度发生次数来表示致险程度,例如洪火的致险程度通常以超过警戒水位的洪水次数来表示。
(2)重现期
水文上常用"重现期"来代替"频率"。所谓重现期是指某随机变量的取值在长时期内平均多少年出现一次,又称多少年一遇。根据研究问题的性质不同,频率P与重现期T的关系有两种表示方法。
① 当为了防洪研究暴雨洪水问题时,一般设计频率<50%,则:
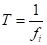 (5.6)
(5.6)
式中,T:重现期,年;:频率,%。
② 当考虑水库兴利调节研究枯水问题时,设计频率>50,则:
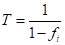 (5.7)
(5.7)
2、常见的概率分布函数
如果能求得样本的概率分布函数,那么求重现期便是十分方便的事情了,常见的概率分布函数有如下几种。
(1)正态分布
① 正态分布
如随机变数X具有下列形式的函度:
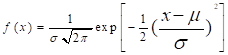 (5.8)
(5.8)
式中,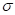 >0,-∞<x<∞,则称X具有正态分布N(
>0,-∞<x<∞,则称X具有正态分布N(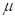 ,
,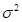 ),它的分布函数是:
),它的分布函数是:
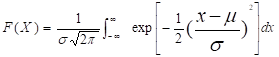 (5.9)
(5.9)
如=0,=1,则称N(0,1)为标准正态分布。
② 对数正态分布
随机变量x的对数值服从正态分布时,称x的分布为对数正态分布。对于两参数正态分布而言,变量x的对数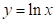 服从正态分布时,y的概率密度函数为:
服从正态分布时,y的概率密度函数为:
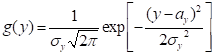 (-∞<y<+∞) (5.10)
(-∞<y<+∞) (5.10)
式中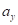 为随机变量y的数学期望;
为随机变量y的数学期望;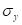 为随机变量y的方差。
为随机变量y的方差。
由此可得到随机变量x的概率密度函数:
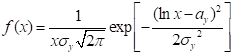 (x>0) (5.11)
(x>0) (5.11)
式(5.11)的概率密度函数包含了和两个参数,故称为两参数对数正态曲线。
因x=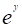 ,故式(5.10)又可写成:
,故式(5.10)又可写成:
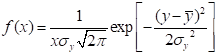 (5.12)
(5.12)
由矩法可以得到各个统计参数,即:
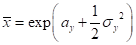 (5.13)
(5.13)
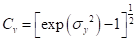 (5.14)
(5.14)
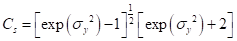 ≥0
(5.15)
≥0
(5.15)
所以,两参数对数正态分布是正偏的。
(2)二项式分布
如随机变数X具有下列形式的函度:
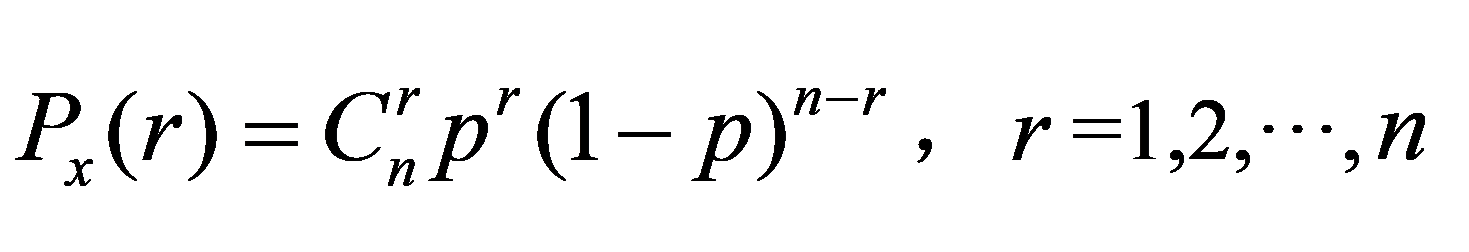 (5.16a)
(5.16a)
则称X具有二项分布b(p,n),其中p为一常数,0<p<1。它恰好是二项式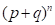 的展开式中的各项,且q=1-p,X的分布函数是:
的展开式中的各项,且q=1-p,X的分布函数是:
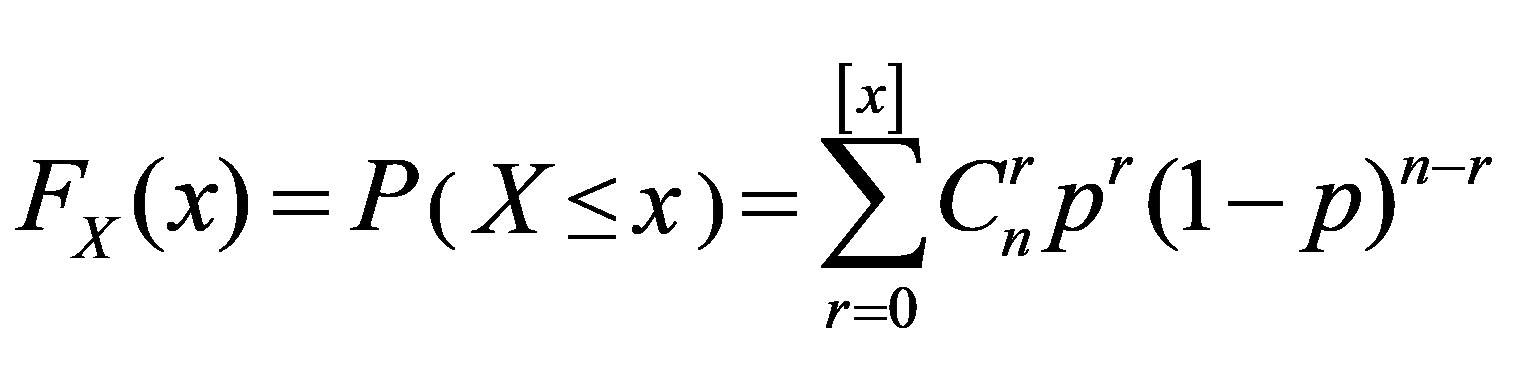 (5.16b)
(5.16b)
(3)泊松分布
如随机变数X取可数多个值r=0,1,2,…的概率分布是:
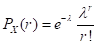 ,
,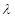 >0
(5.17a)
>0
(5.17a)
则称X 是泊松分布p(r;),其中>0为一常数。
注意这时也有
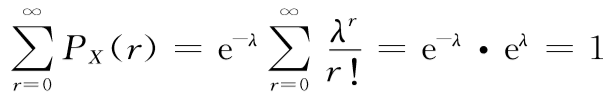
相应地,X的分布函数是
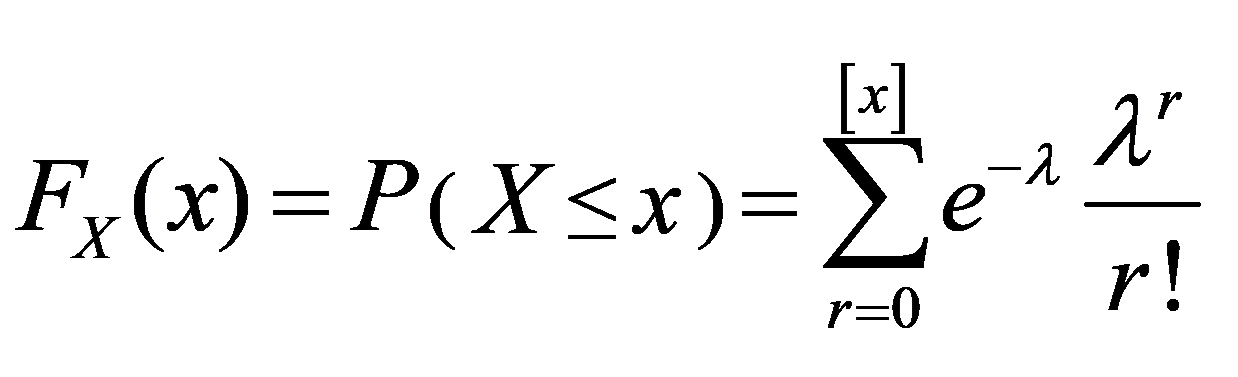 (5.17b)
(5.17b)
(4)柯西概率分布函数
为某种气象要素或灾害服从柯西分布,x<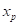 的概率为:
的概率为:
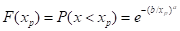 (5.18)
(5.18)
则x≥的概率为:
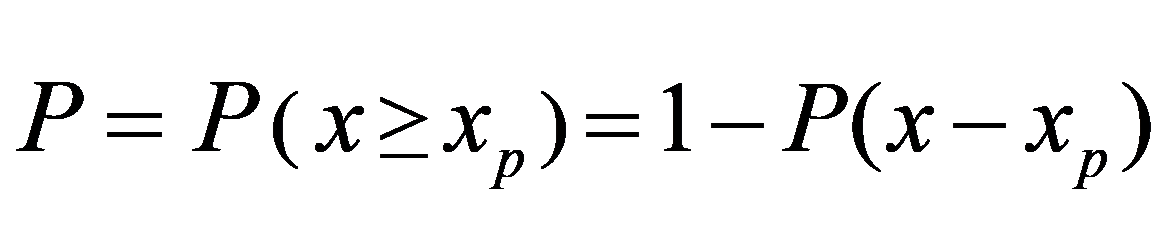 (5.19)
(5.19)
水利和气象部门经常用皮尔逊曲线和Fisher/Gumbel分布求多少年一遇的极值。
3、皮尔逊Ⅲ型曲线
(1)皮尔逊Ⅲ型曲线
皮尔逊Ⅲ型曲线是一条一端有限一端无限的不对称单峰、正偏曲线,数学上常称伽玛分布,其概率密度函数为:
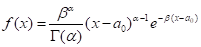 (5.20)
(5.20)
式中: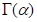 -
-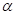 的伽玛函数;、
的伽玛函数;、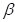 、
、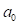 ―分别为皮尔逊Ⅲ型分布的形状尺度和位置未知参数,>0,>0
。
―分别为皮尔逊Ⅲ型分布的形状尺度和位置未知参数,>0,>0
。
显然,三个参数确定以后,该密度函数随之可以确定。可以推论,这三个参数与总体三个参数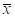 、
、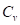 、
、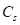 具有如下关系:
具有如下关系:
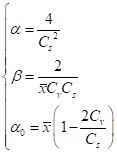 (5.21)
(5.21)
(2)皮尔逊Ⅲ型频率曲线及其绘制
计算中,一般需要求出指定频率P所相应的随机变量取值,也就是通过对密度曲线进行积分,即:
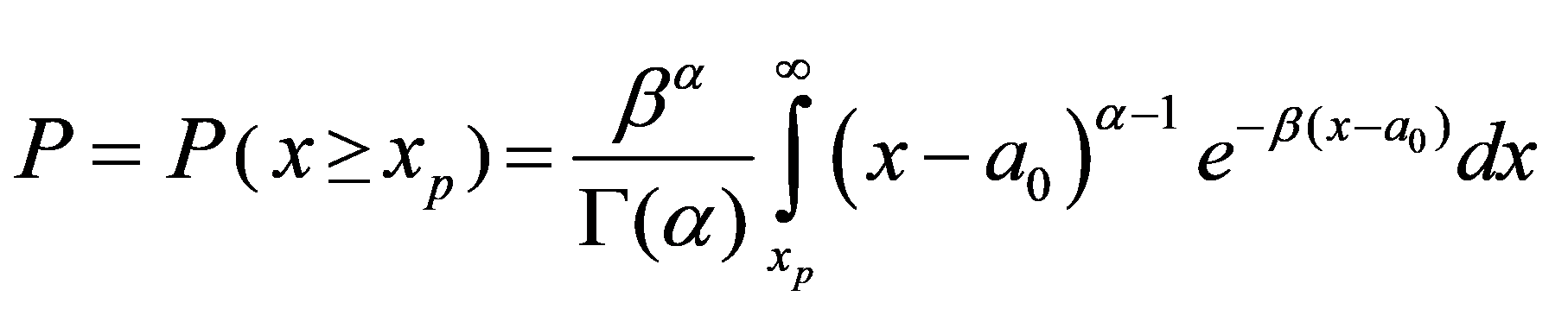 (5.22)
(5.22)
求出等于及大于的累积频率P值。直接由式(5.22)计算P值非常麻烦,实际做法是通过变量转换,变换成下面的积分形式:
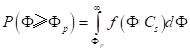 (5.23)
(5.23)
式(5.23)中被积函数只含有一个待定参数,其它两个参数、都包含在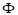 中。x是标准化变量,
中。x是标准化变量,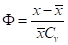 称为离均系数。的均值为0,标准差为1。因此,只需要假定一个值,便可从式(5.23)通过积分求出p与之间的关系。对于若干个给定的值,和p的对应数值表(表5.2),由美国福斯特和前苏联雷布京制作。由就可以求出相应频率p的x值:
称为离均系数。的均值为0,标准差为1。因此,只需要假定一个值,便可从式(5.23)通过积分求出p与之间的关系。对于若干个给定的值,和p的对应数值表(表5.2),由美国福斯特和前苏联雷布京制作。由就可以求出相应频率p的x值:
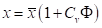 (5.24)
(5.24)
表5.2 皮尔逊Ⅲ型频率曲线的离均系数>值表(摘录)
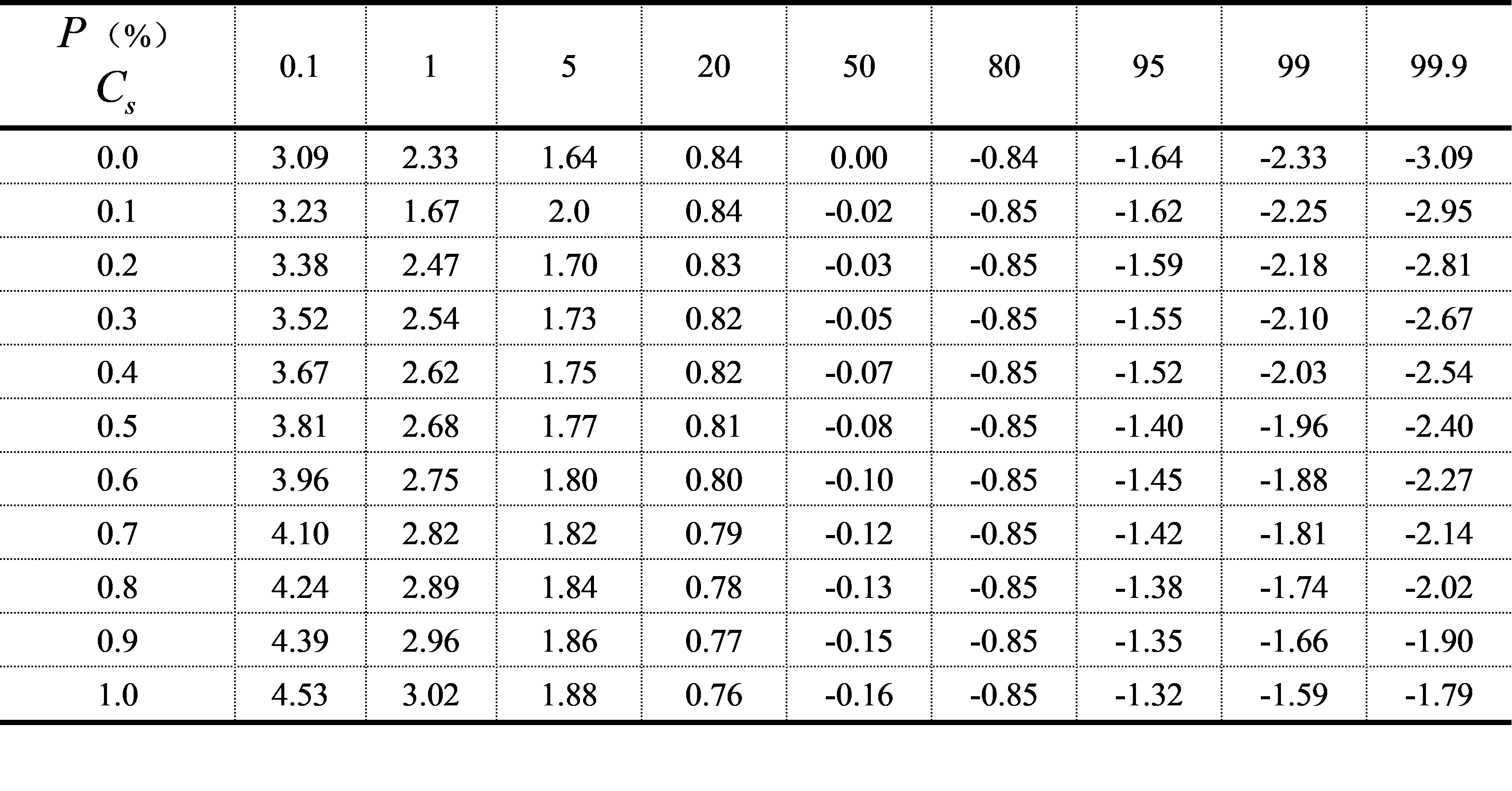
(3)皮尔逊Ⅲ型频率曲线的应用
在频率计算时,由已知的值,查值表得出不同的P的值,然后利用已知的、,通过式(5.24)即可求出与各种P相应的x值,从而可绘制出皮尔逊Ⅲ型频率曲线。
当等于的一定倍数时,P-Ⅲ型频率曲线的模比系数KP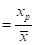 (表5.3)。频率计算时,由已知的和可以从附表5.3中查出与各种频率P相对应的KP值,然后即可算出与各种频率对应的x=KP。有了P和x的一些对应值,即可绘制出皮尔逊Ⅲ型频率曲线。
(表5.3)。频率计算时,由已知的和可以从附表5.3中查出与各种频率P相对应的KP值,然后即可算出与各种频率对应的x=KP。有了P和x的一些对应值,即可绘制出皮尔逊Ⅲ型频率曲线。
表5.3 皮尔逊Ⅲ型频率曲线的模比系数KP 值表(摘录,
= 2)

4、Fisher/Gumbel分布
假设X为一随机变量(例如某地的日最高气温或日降水量),而令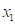 ,
,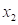 ,…
,…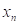 为X的一组随机样本,则若按由小到大的次序排列这个样本,就可写为:
为X的一组随机样本,则若按由小到大的次序排列这个样本,就可写为: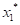 <
<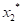 …<
…<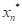 。
。
显然,这里所有的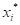 (i=1, 2,…n)都是所谓次序随机变量,其中就是该样本的极大值,而就是该样本的极小值。所谓极值分布就是代表
或的随机变量的概率分布,即对次序随机变量(又称次序统计量):
(i=1, 2,…n)都是所谓次序随机变量,其中就是该样本的极大值,而就是该样本的极小值。所谓极值分布就是代表
或的随机变量的概率分布,即对次序随机变量(又称次序统计量):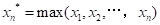 ,
,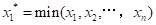 。寻求其分布函数和分布密度,显然,和取决于n的大小和原始变量x的分布形式。现以极大值为例,可以推得和的分布函数分别为:
。寻求其分布函数和分布密度,显然,和取决于n的大小和原始变量x的分布形式。现以极大值为例,可以推得和的分布函数分别为:
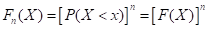 、
、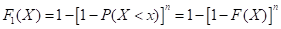 。
。
20世纪20年代,Fisher与Tippett(1928)证明了当取样长度n→∞时,和极值具有渐近分布函数,并概括了与原始分布对应的通常有3种类型的极限概率分布,即渐近的极值分布模型。
(1)第I型(指数原始分布或双指数原始分布)
第I型分布函数为:
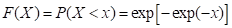 -∞<x<∞
-∞<x<∞
其标准化形式为:
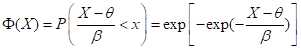 -∞<x<∞ (5.25)
-∞<x<∞ (5.25)
此型称为Fisher-Tippettd I型分布。因最初由Gumbel(1948)用于水文学的洪水极值计算, 故又称此分布型为Gumbel分布。
(2)第II型(柯西型原始分布)
第II型分布函数为:
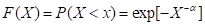 , x>0
, x>0
其标准化形式为:
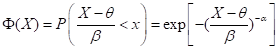 0
<x<∞, >0
(5.26)
0
<x<∞, >0
(5.26)
(3)第III型(有界型)
第III型分布函数为:
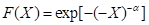 >0, x≤0
>0, x≤0
其标准化形式为:
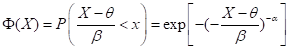 x≤ 0 (5.27)
x≤ 0 (5.27)
此型适用于极小值的分布, 可以证明它就是Weibull 分布。
(4)极值分布模式的参数估计
常用于气象和水文研究的极值分布,多以第I型(即Gumbel分布)为主,其参数仅有2个,常用矩法、Gumbel法、最小二乘法和极大似然法估计参数。近年来,发展了一种概率加权矩法(PWM)估计参数,后又发展出L-矩法估计或与PWM估计相结合的方法。
为了求得气象灾害风险样本的概率分布符合哪一种密度函数,首先需要对样本序列进行分布型判别,采用偏度-峰度检验法,通过检验且样本数大于30,便可以用这种概率分布密度函数求任何强度的致灾因子的重现期了,或者反过来,由重现期求致灾因子强度的量值。